数据库-mysql-小林coding-日志篇
本系列笔记为作者在跟随小林coding学习的时候做的笔记。感谢小林大大。
- undo log(回滚日志):Innodb 存储引擎层生成的日志,原子性,用于事务回滚和 MVCC。
- redo log(重做日志):是 Innodb 存储引擎层生成的日志,持久性,用于故障恢复;
- binlog (归档日志):Server 层生成的日志,用于数据备份和主从复制;
undo log
MySQL 会为没有begin和commit的单个语句隐式开启事务
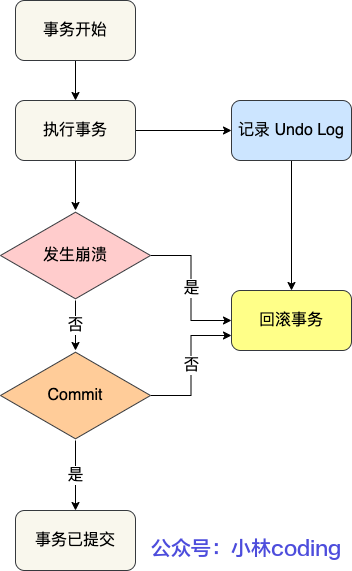
- 插入一条记录,存记录的主键值,回滚时删掉这个主键值
- 删除一条记录,存这条记录的所有内容,回滚时插入到表中
- 更新一条记录,存被更新的列的旧值,回滚时更新为旧值
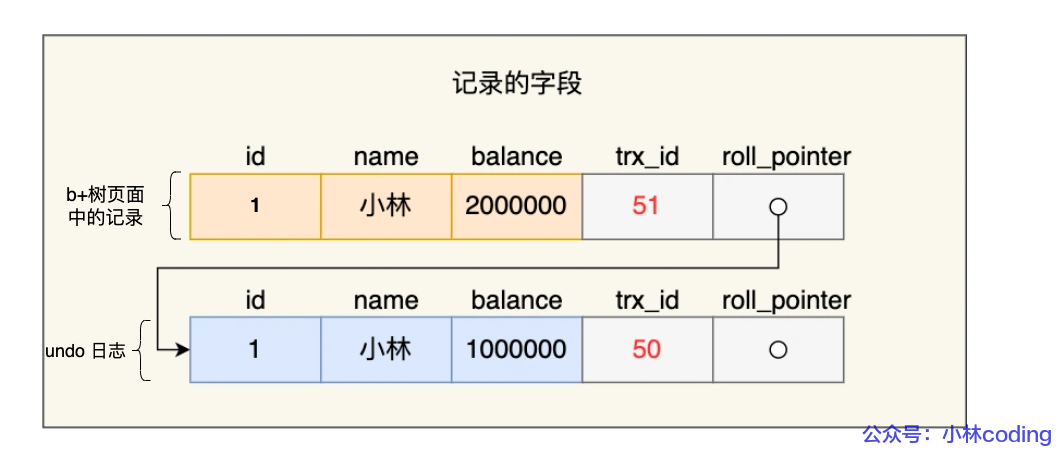
每条undo日志都有 roll_pointer 指针和trx_id 事务id
- trx_id 存修改操作的事务
- roll_pointer 指针指向被修改的记录。该指针形成的链表就叫版本链
undo log 两大作用:
- 实现事务回滚,保障事务的原子性
- 实现 MVCC(多版本并发控制)关键因素之一
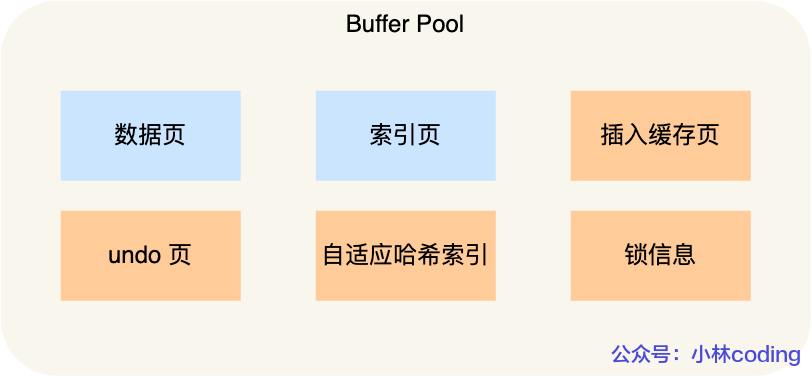
Buffer Pool
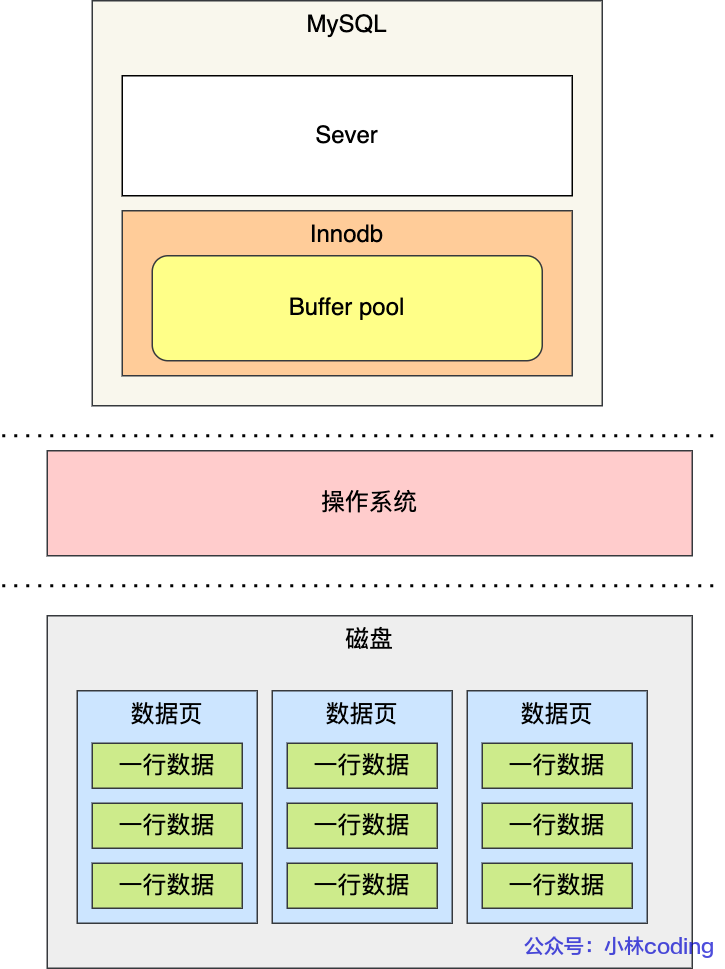
- 读取数据需要先从磁盘读取到buffer pool,再从buffer pool读取
- 修改数据时,仅修改buffer pool,并将响应的页设置为脏页,最后在合适的时候将脏页刷新到磁盘,这也叫做WAL (Write-Ahead Logging)技术
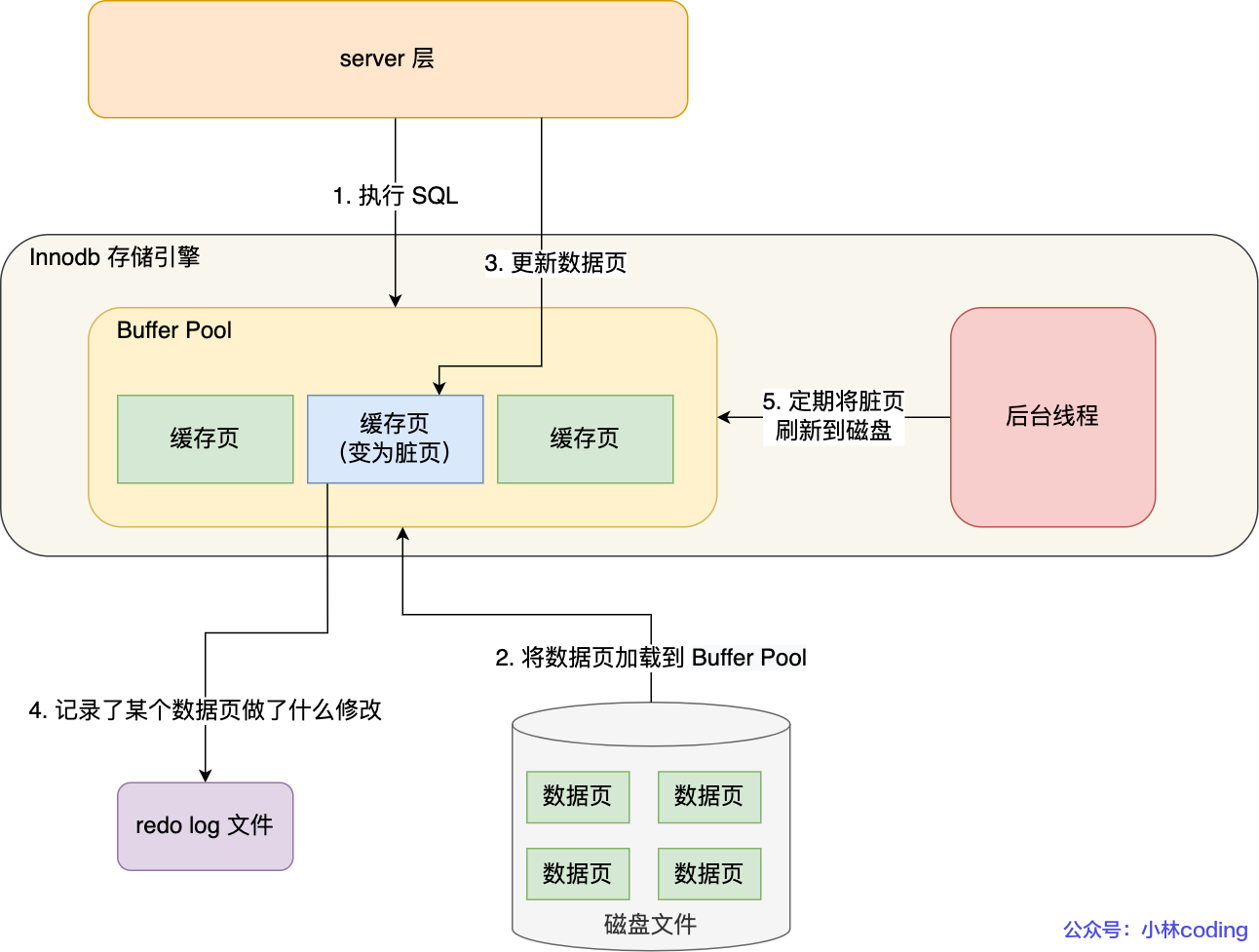
redo log
对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新时就会产生redolog日志,先写脏页再写redolog
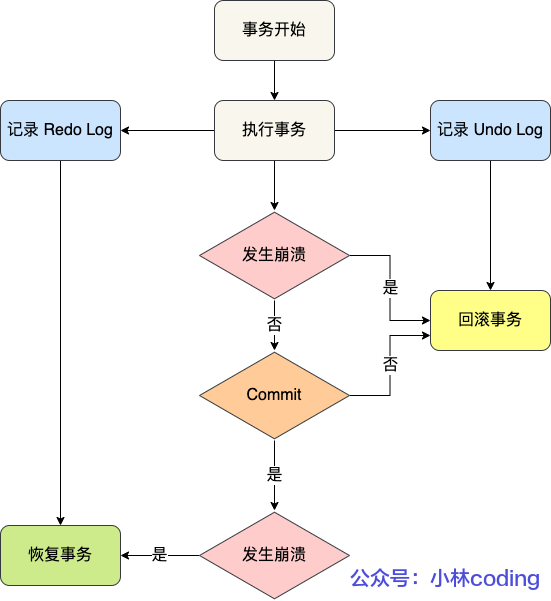
redo log 和 undo log 区别:
- redo log 记录事务「完成后」的数据状态,更新之后的值
- undo log 记录事务「开始前」的数据状态,更新之前的值
redo log作用:
- 实现事务的持久性,让 MySQL 有 crash-safe 的能力
- 将写操作从「随机写」变成了「顺序写」,提升 MySQL 写入磁盘的性能
redo log 不是直接写入磁盘而是写入 redo log buffer,在后续持久化到磁盘
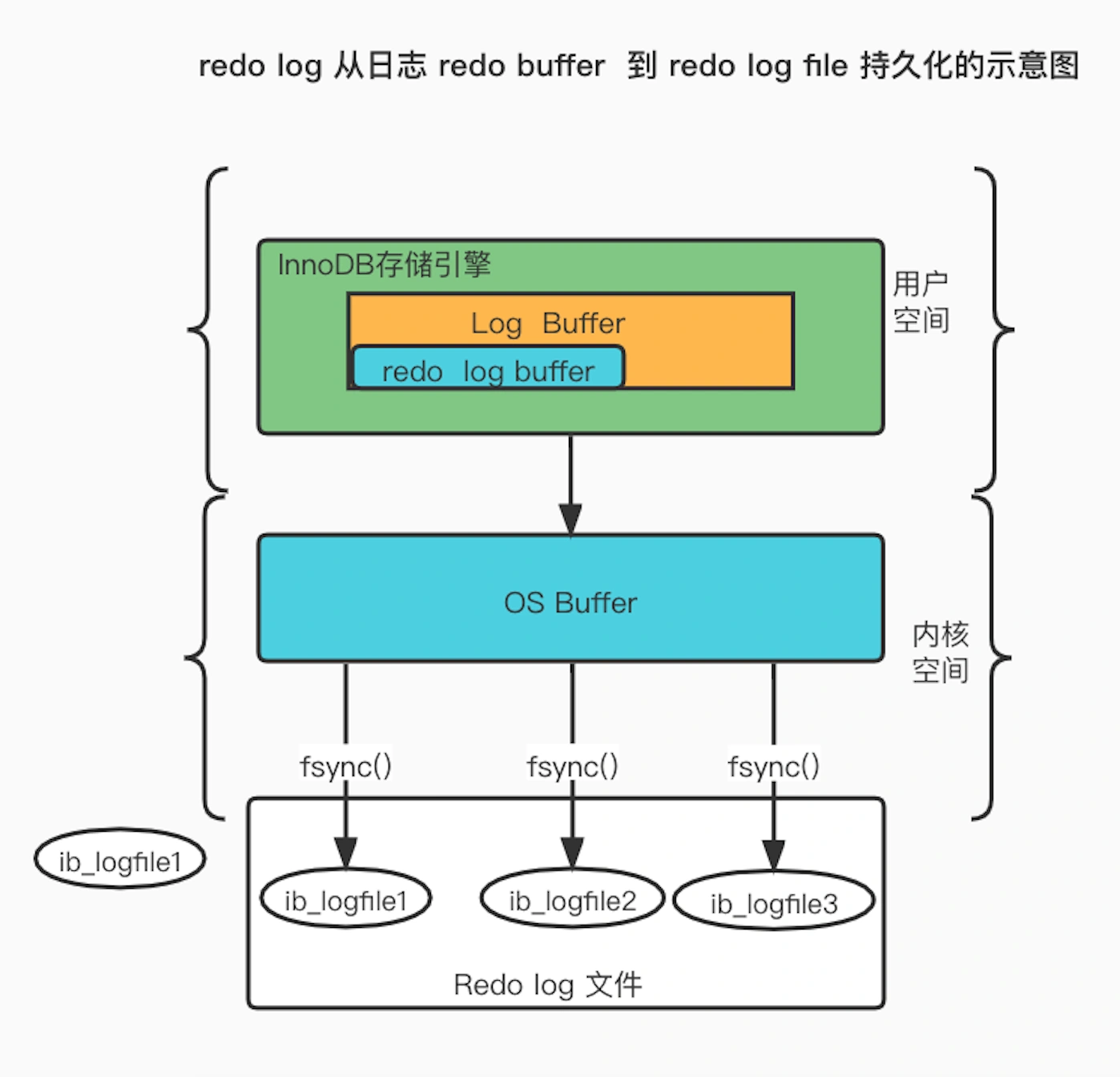
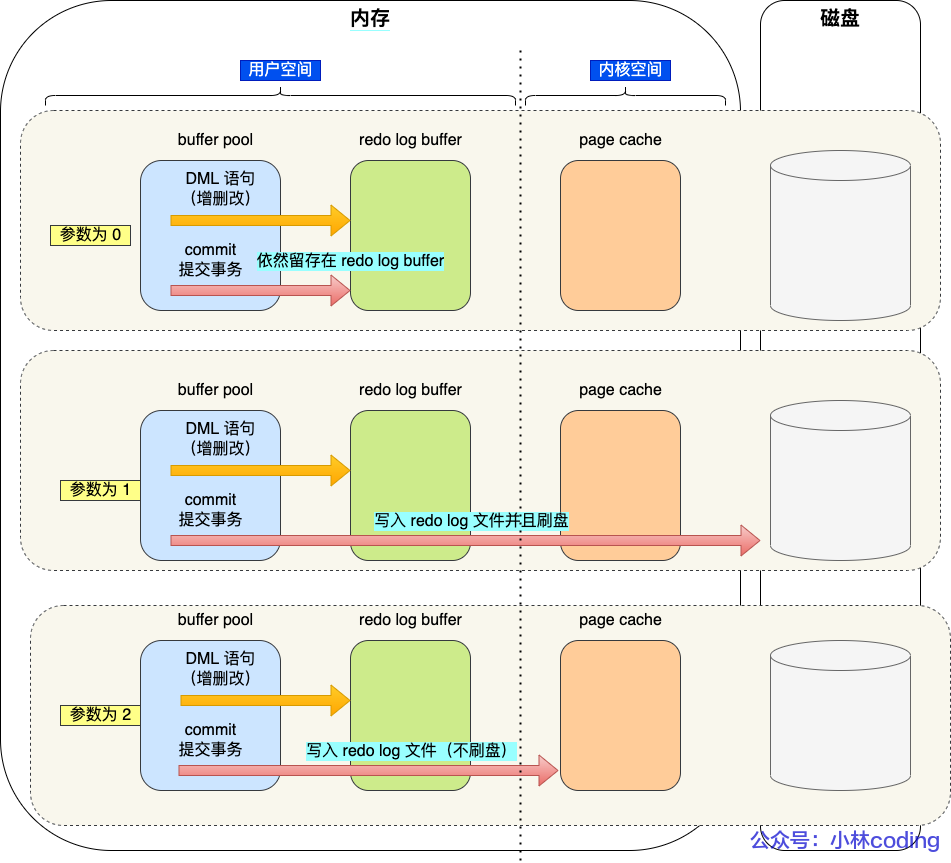
刷盘时机:
- MySQL 正常关闭
- redo log buffer空闲空间少于一半
- InnoDB 的后台线程每隔 1 秒
- innodb_flush_log_at_trx_commit参数控制每次事务提交时的操作,0不主动触发,1持久化到磁盘,2持久化到page cache(操作系统的页缓存)
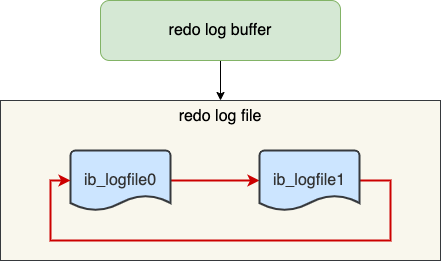
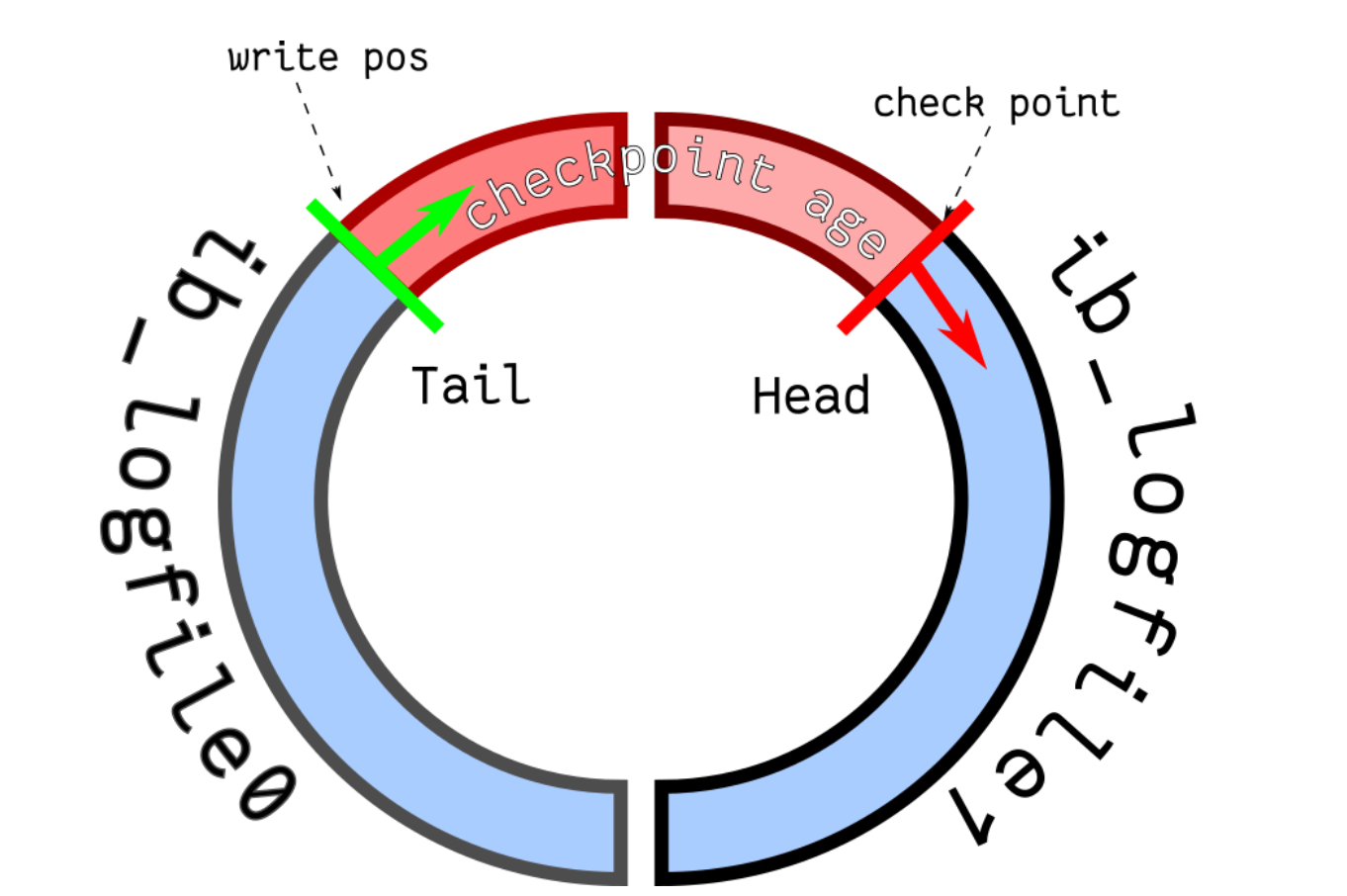
redo log 文件写满了怎么办
重做日志文件组(redo log Group)由有 2 个 redo log 文件组成,ib_logfile0 和 ib_logfile1 。两个文件循环写。满了就阻塞mysql将脏页写入磁盘,同时清理可以擦除的redolog
binlog
binlog由服务层生成(可以供其他存储引擎使用),redolog和undolog由innodb存储层生成
一条更新操作后生成一条 binlog,事务提交时将该事务执行过程中产生的所有 binlog 写入 binlog 文件。
binlog 文件只记录所有数据库表结构变更和表数据的修改
主从复制依赖于 binlog。复制的过程是将 binlog 中的数据从主库传输到从库上。该过程默认不需要阻塞主库执行事务(异步)
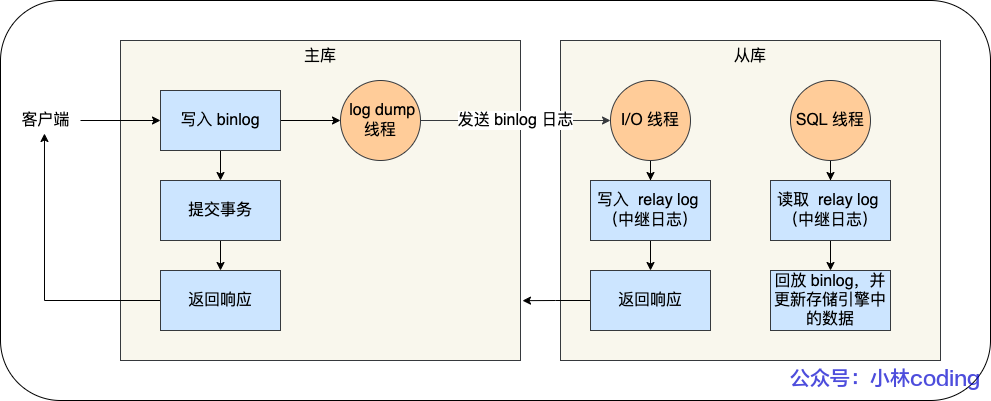
主从复制过程:主库写 Binlog=》从库同步 Binlog=》从库回放 Binlog
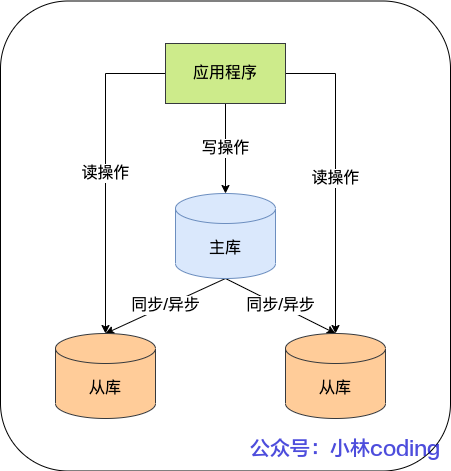
一个主库一般跟 2~3 个从库(1 套数据库,1 主 2 从 1 备主)
主从复制模型:
- 同步复制:阻塞直到所有从库成功响应,性能太差
- 异步复制(默认模型):不阻塞
- 半同步复制:阻塞直到某一个从库成功响应
binlog日志写到 binlog cache(Server 层的 cache),事务提交的时候再写到 binlog 文件中。一个事务的 binlog 是不能被拆开的
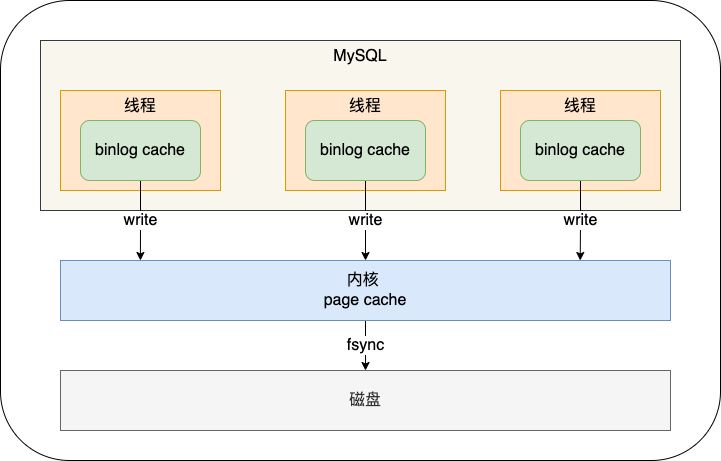
sync_binlog 控制binlog 每次提交事务时的操作
- 0:只write,不fsync
- 1:write后立刻fsync
- N:write,然后提交N个事务后fsync
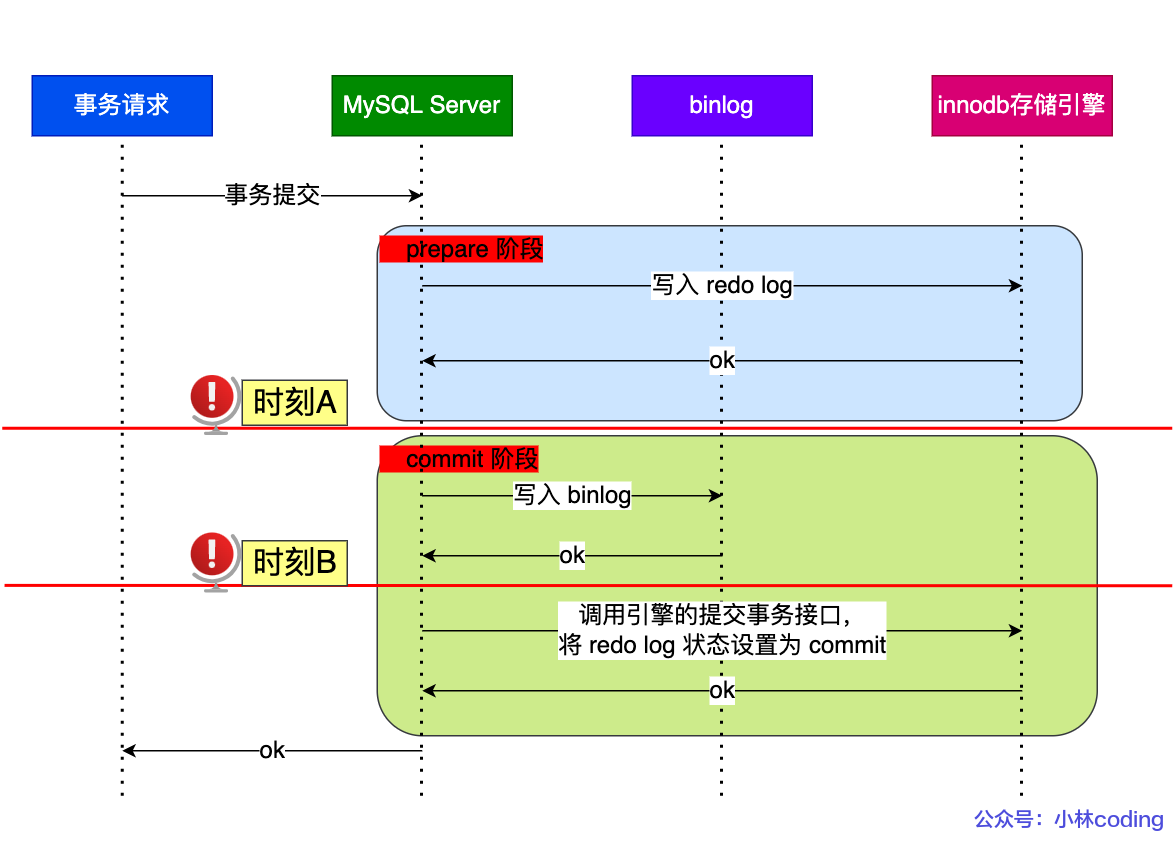
两阶段提交
MySQL 为了避免出现redo log 和 binlog 之间的逻辑不一致的问题,使用了「两阶段提交」来解决
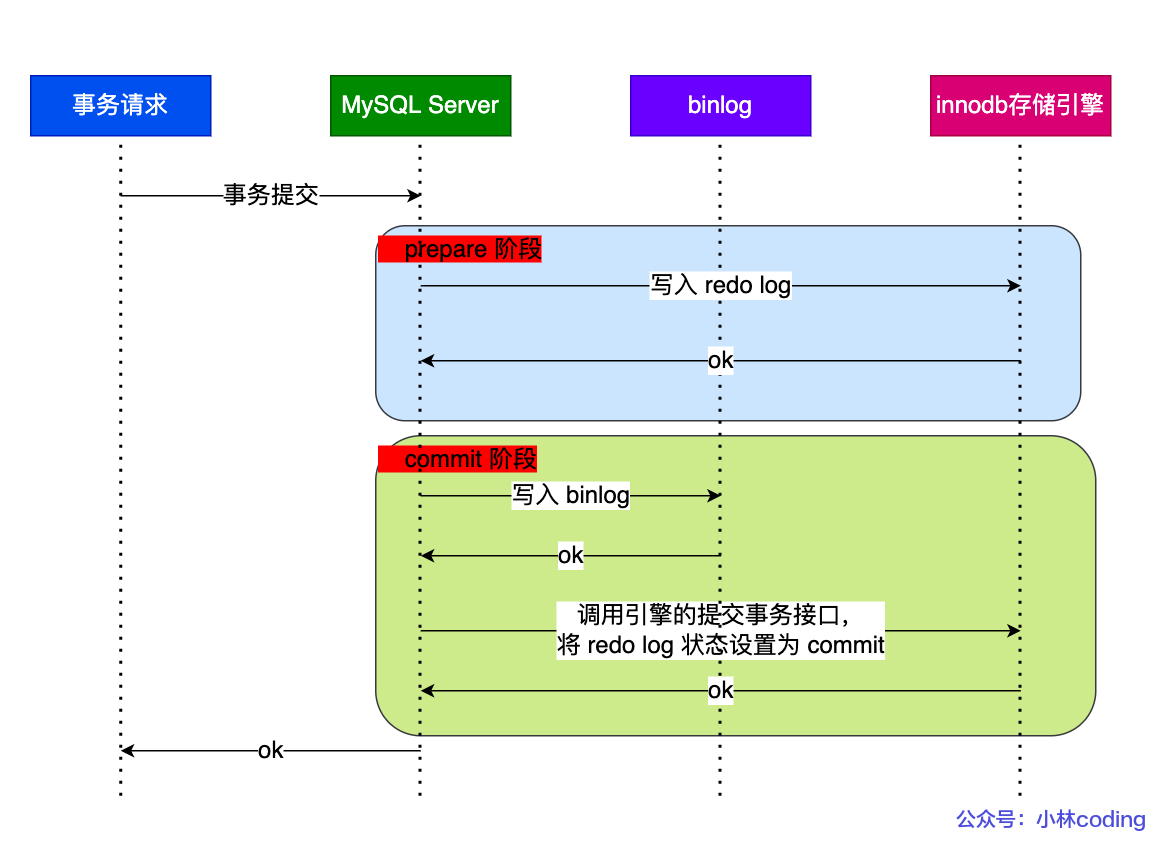
两阶段提交都会存储XID
异常重启通过检查binlog中有没有XID来判断异常时机。如果有则是时刻A,需要进行事务回滚;如果没有则是时刻B,直接将redolog状态修改为commit即可。