数据库-redis-小林coding-数据类型篇
本系列笔记为作者在跟随小林coding学习的时候做的笔记。感谢小林大大。
逻辑数据类型

String
int 或 SDS实现

编码方式和ptr指向的数据结构有关

- 保存文本数据或二进制数据
- 获取字符串长度的时间复杂度是 O(1)
- 拼接字符串不会造成缓冲区溢出
value 最多可以容纳的数据长度是 512M(2^28)
常用指令
- SET key value:设置 key-value 类型的值
- GET key:根据 key 获得对应的 value
- EXISTS key:判断某个 key 是否存在
- STRLEN key:返回 key 所储存的字符串值的长度
- DEL key:删除某个 key 对应的值
批量操作
- MSET key1 value1 key2 value2:批量设置 key-value 类型的值
- MGET key1 key2:批量获取多个 key 对应的 value
字符串的内容为整数的时候可以使用)
- INCR key:将 key 中储存的数字值增一
- INCRBY key n:将key中存储的数字值加 n
- DECR key:将 key 中储存的数字值减一
- DECRBY key n:将key中存储的数字值减 n
过期(默认为永不过期)
- EXPIRE key n:设置 key 在 n 秒后过期(该方法是针对已经存在的key设置过期时间)
- TTL key:查看数据还有多久过期
- SET key value EX n:设置 key-value 类型的值,并设置该key的过期时间为 n 秒
- SETEX key n value:设置 key-value 类型的值,并设置该key的过期时间为 n 秒
不存在就插入
- SETNX key value:不存在就插入(not exists)
应用场景:缓存对象(json,mset),常规计数,分布式锁(SETNX)和共享 Session 信息
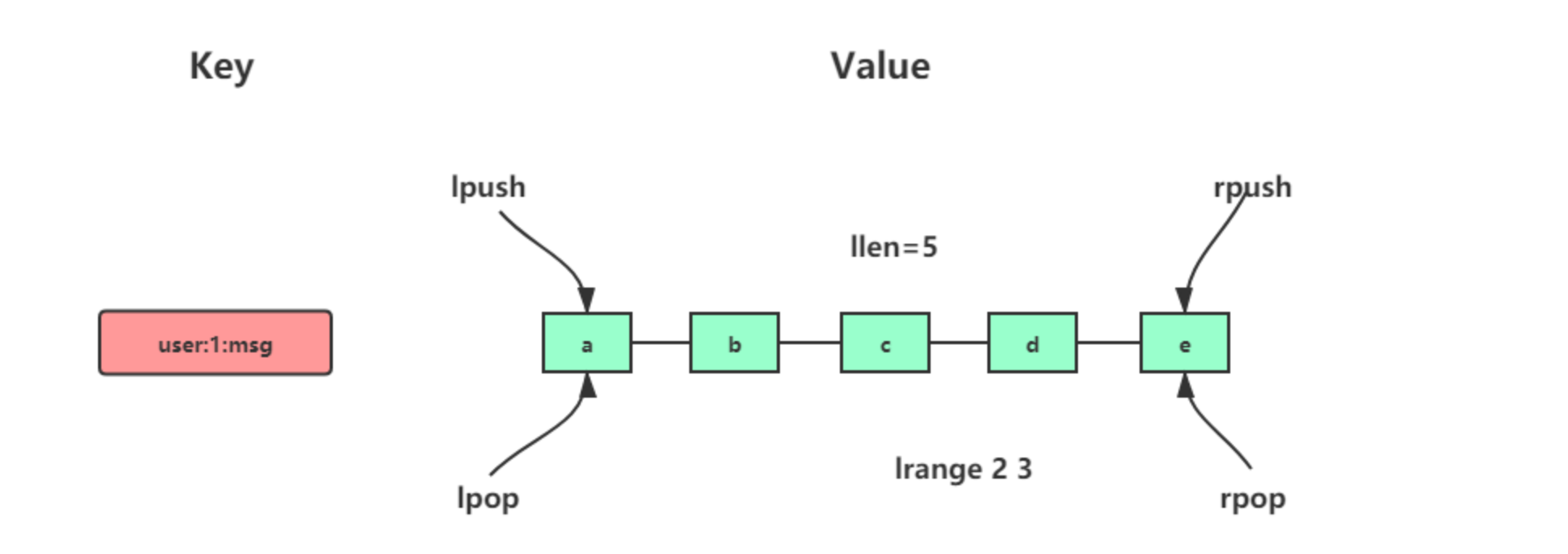
List
按照插入顺序排序,可以操作头部和尾部
Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了
最大长度为 2^32 - 1
常用命令
- LPUSH key value [value …]:将一个或多个值value依次插入到key列表最左边
- RPUSH key value [value …]:将一个或多个值value依次插入到key列表最右边
- LPOP key:移除并返回key列表的最左元素
- RPOP key:移除并返回key列表的最右元素
- LRANGE key start stop:返回列表key中从左往右索引为[start,stop]区间内的元素,索引从0开始
- BLPOP key [key …] timeout:从key列表左边弹出一个元素,没有元素就阻塞timeout秒,timeout=0一直阻塞
- BRPOP key [key …] timeout:从key列表右边弹出一个元素,没有元素就阻塞timeout秒,timeout=0一直阻塞
- RPOPLPUSH source destination
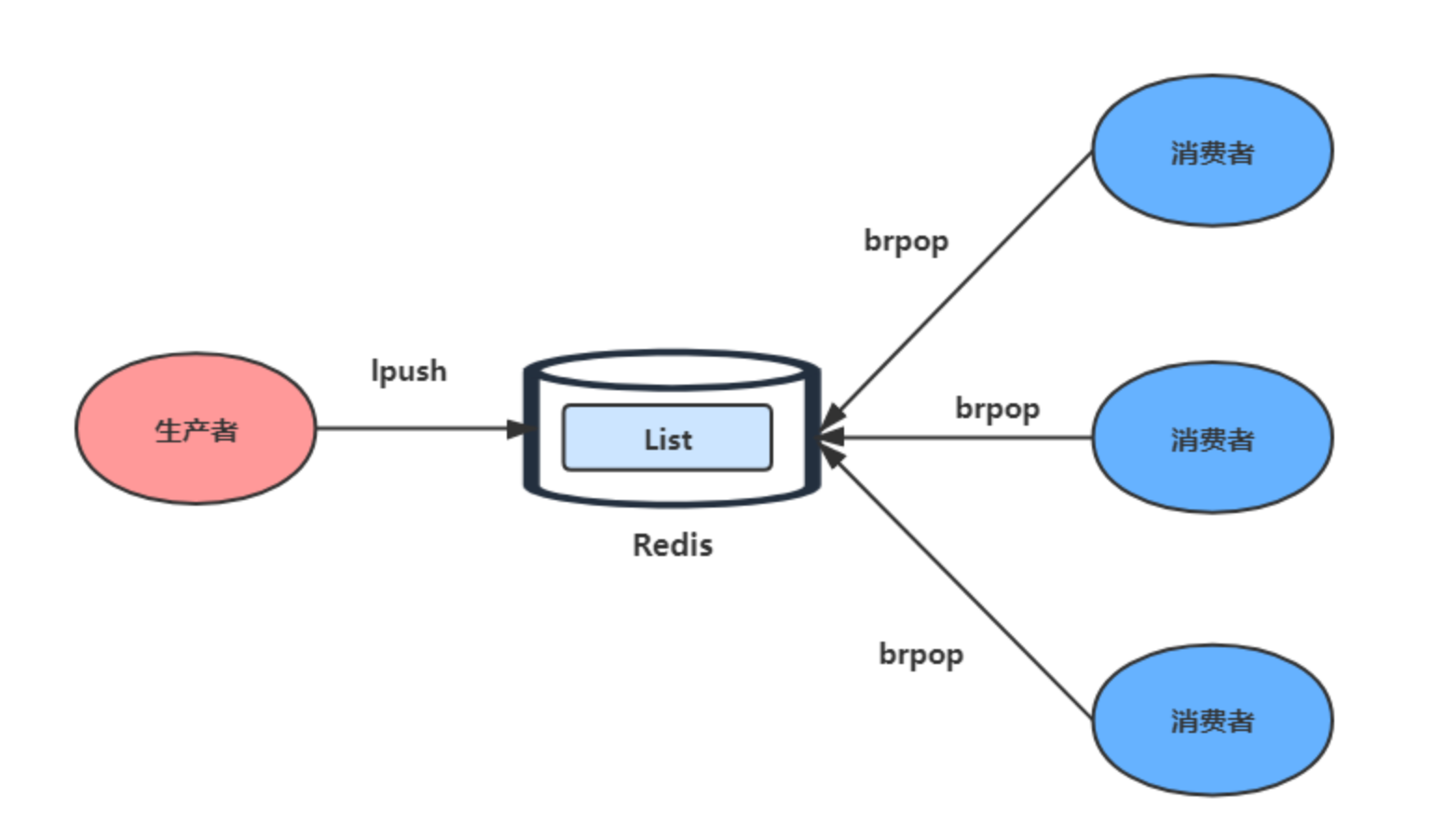
应用场景:消息队列
- 消息保序:使用 LPUSH + RPOP
- 阻塞读取:使用 BRPOP
- 重复消息处理:生产者自行实现全局唯一 ID
- 消息的可靠性:使用 BRPOPLPUSH
Hash
Hash 是一个键值对(key - value)集合
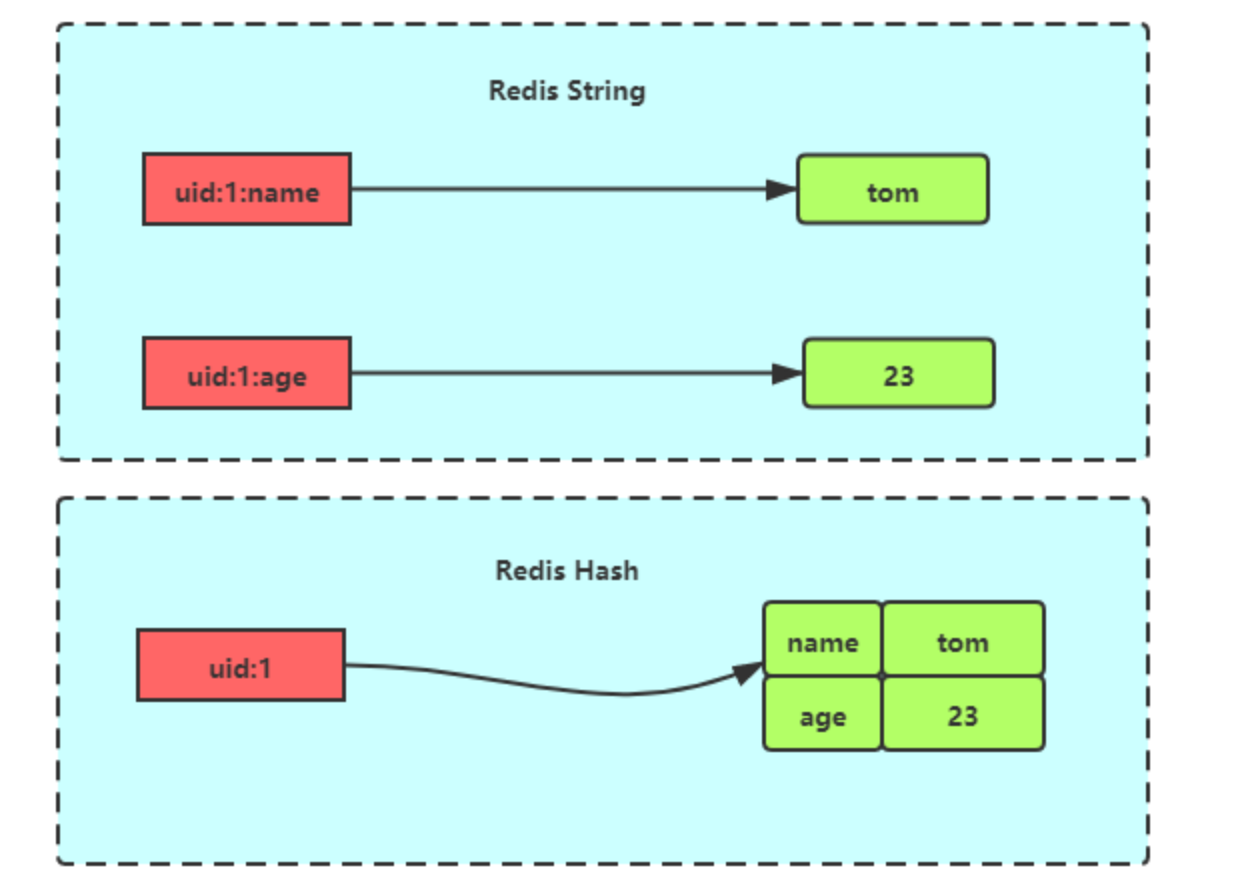
元素个数最大为512个,所有值小于64Byte使用压缩列表
否则使用哈希表
常用命令
- HSET key field value:哈希表key存储一个的键值对(field,value)
- HGET key field:获取哈希表key中field键的值
- HMSET key field value [field value…]:哈希表key中存储多个键值对
- HMGET key field [field …]:批量获取哈希表key中多个field键的值
- HDEL key field [field …]:删除哈希表key中的field键值对
- HLEN key:返回哈希表key中field的数量
- HGETALL key:返回哈希表key中所有的键值对
- HINCRBY key field n:为哈希表key中field键的值加上增量n
应用场景:缓存对象,购物车
Set
Set是无序并唯一的值集合
最多2^32-1个元素
小于512个元素,使用整数集合实现
否则使用哈希表实现
常用命令
- SADD key member [member …]:往集合key中存入元素member,元素存在则忽略
- SREM key member [member …]:从集合key中删除元素member
- SMEMBERS key:获取集合key中所有元素
- SCARD key:获取集合key中的元素个数
- SISMEMBER key member:判断member元素是否存在于集合key中
- SRANDMEMBER key [count]:从集合key中随机选出count个元素,元素不从key中删除
- SPOP key [count]:从集合key中随机选出count个元素,元素从key中删除
Set运算操作
- SINTER key [key …]:返回交集运算的结果
- SINTERSTORE destination key [key …]:将交集结果存入新集合destination中
- SUNION key [key …]:返回并集运算的结果
- SUNIONSTORE destination key [key …]:将并集结果存入新集合destination中
- SDIFF key [key …]:返回差集运算的结果
- SDIFFSTORE destination key [key …]:将差集结果存入新集合destination中
应用场景:点赞,共同关注
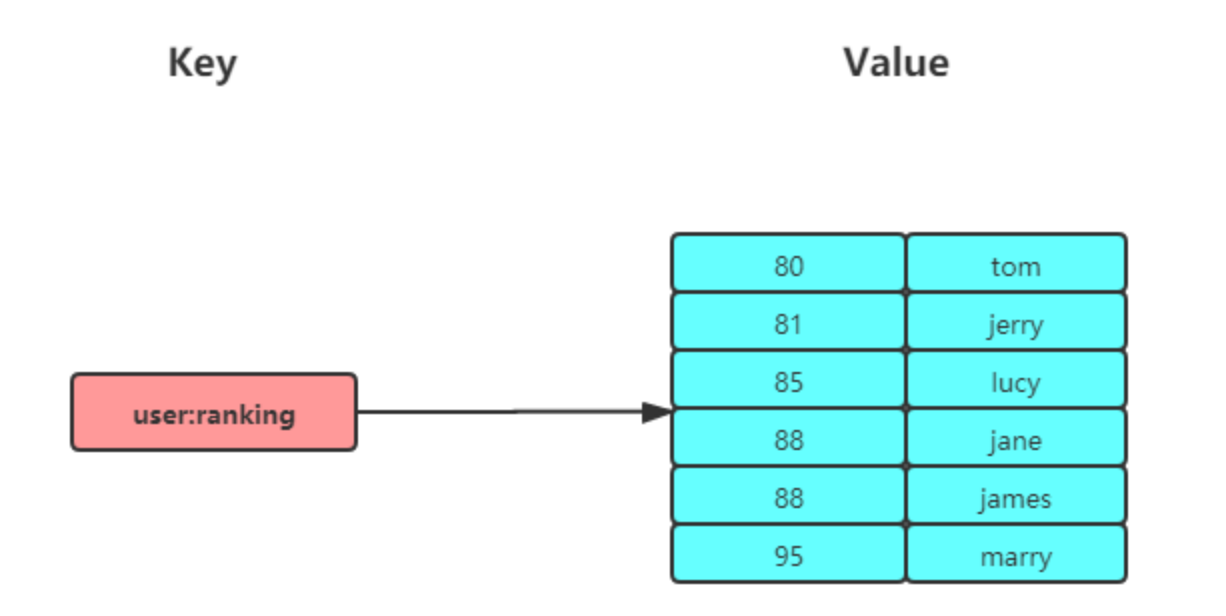
Zset
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),分值可以重复
每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值
元素小于128个,每个元素值小于64字节时用listpack实现
否则使用跳表实现
常用命令
- ZADD key score member [[score member]…]:插入带score分值的member元素
- ZREM key member [member…]:删除member元素
- ZSCORE key member:member元素的分值
- ZCARD key:元素个数
- ZINCRBY key increment member:元素member的分值加上increment
- ZRANGE key start stop [WITHSCORES]:升序获取分值排名start到stop的元素,以排名以0开始
- ZREVRANGE key start stop [WITHSCORES]:降序获取分值排名start到stop的元素,以排名以0开始
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]:升序获取分数值在[min,max]区间的元素
- ZRANGEBYLEX key min max [LIMIT offset count]:按字典序升序获取元素值在[min,max]区间的元素
Zset 运算操作(没有支持差集运算)
- ZUNIONSTORE destkey numberkeys key [key…]:并集计算,相同key的分值score相加
- ZINTERSTORE destkey numberkeys key [key…]:交集计算,相同key的分值score相加
应用场景:排行榜,电话、姓名排序
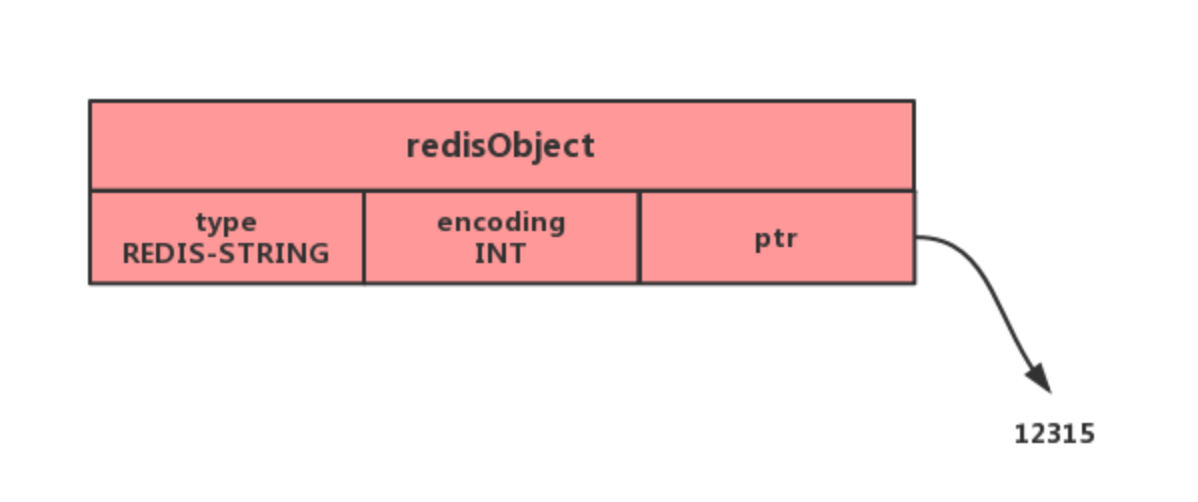
物理结构

- type,标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象)
- encoding,标识该对象使用了哪种底层的数据结构
- ptr,指向底层数据结构的指针
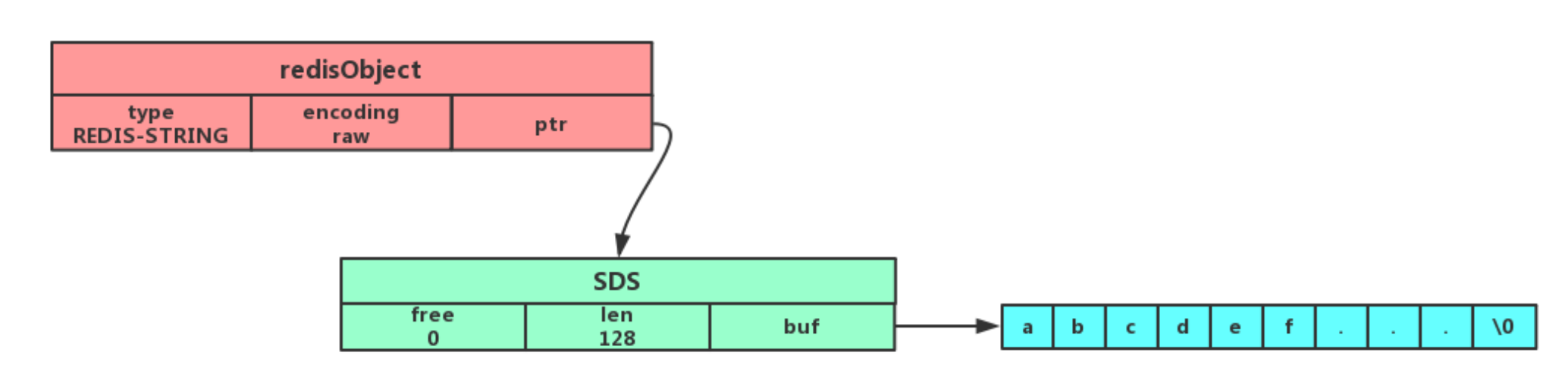
SDS

O(1)复杂度获取字符串长度
二进制安全,可存储包含 “\0” 的数据
不会发生缓冲区溢出,Redis自动判断alloc - len,当判断出缓冲区大小不够用时,Redis 会自动扩大 SDS 的空间大小
小于 1 MB翻倍扩容,超过 1 MB 则 newlen + 1MB
节省内存空间,取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐
链表

压缩列表

连锁更新:前一个节点长度小于 254 字节,prevlen占用1 字节的空间,大于等于 254 字节,占用5 字节的空间。插入节点大于254字节,后面的都属于[250,254)字节时就会连锁更新,每个节点都要修改prevlen的空间分配
哈希表

Redis 采用了「链式哈希」来解决哈希冲突
渐进式 rehash 步骤:
- 给「哈希表 2」 分配空间,一般翻一倍大小
- 在 rehash 期间,新增、删除、查找或者更新操作会顺便将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上
- 「哈希表 1 」的所有 key-value 迁移到「哈希表 2」时释放「哈希表 1 」,并将「哈希表 2」设置为「哈希表 1 」
rehash条件:负载因子=哈希表已保存键值对数/哈希表大小
- 负载因子大于等于1且没有进行持久化操作(记录RDB快照或AOF重写)时
- 负载因子大于等于5时
整数集合
整数集合升级:当新元素需要使用更大的编码方式时,先扩容,然后将旧元素重新赋值,最后添加新元素

跳表
跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表

为什么用跳表而不用平衡树:
- 内存占用少
- 范围查找简单
- 不需要调整子树
quicklist

listpack

listpack 没有压缩列表中记录前一个节点长度的字段了