机器学习-深度学习-Pytorch
教程
tensors张量
张量是一种特殊的数据结构,与数组和矩阵非常相似
使用张量对模型的输入和输出以及模型的参数进行编码
导入张量
|
|
初始化张量
- 直接来自已有数据:
x_data = torch.tensor([[1, 2],[3, 4]]) - 来自 NumPy 数组(也可以转换成NumPy数组):
|
|
- 从另一个张量(除非明确覆盖,否则新张量保留参数张量的属性(形状、数据类型)):
|
|
- 使用随机值或常数值
shape是张量维度的元组:shape = (2,3,)
|
|
张量的属性
张量属性描述了它们的形状、数据类型和存储它们的设备
|
|
张量运算
所有的运算方式见官网文档
默认情况下,张量是在 CPU 上创建的,使用.to方法将张量显式移动到 GPU
|
|
- 标准的类似 numpy 的索引和切片:
|
|
- torch.cat沿给定维度连接一系列张量
|
|
- 算术运算
- 单元素张量:使用聚合函数获取聚合值对象,然后使用聚合值对象的item()方法转换为python数值
|
|
- 就地操作:将结果存储到操作数中的操作称为就地操作,这个方法会改变原张量,方法名以
_符结尾
|
|
会立即丢失历史记录,求导数可能会出问题,不鼓励使用
桥接 NumPy
张量的numpy方法转换为 NumPy 数组,这种转换类似于传指针,对张量的改变会等价改变numpy数组
|
|
NumPy 数组到 Tensor,对numpy数组的改变会等价改变张量
|
|
数据集和数据加载器
实现一个数据集类: __init__, __len__, 和 __getitem__ 方法
Transforms变换
使用Transform对数据进行一些操作,使其适合训练。
- ToTensor():将 PIL 图像或 NumPy 转换ndarray为FloatTensor. 并在 [0., 1.] 范围内缩放图像的像素强度值
- Lambda 转换:Lambda 转换应用任何用户定义的 lambda 函数
构建神经网络
神经网络由对数据执行操作的层/模块组成。torch.nn命名空间提供了构建自己的神经网络所需的所有构建块。
PyTorch 中的每个模块都是nn.Module 的子类。
神经网络本身就是一个由其他模块(层)组成的模块。
设置训练设备
检查 torch.cuda 是否可用,不可用使用 CPU
|
|
定义类
通过子类化nn.Module来定义神经网络,在 __init__ 方法中初始化神经网络层,在 forward 方法中实现对输入数据的操作,比如下面的NeuralNetwork类
|
|
创建 NeuralNetwork 实例,并将其移动到device
|
|
使用该模型只需将输入数据传递给它(使用__Call__方法),不要直接调用forward方法
|
|
模型层
分解 FashionMNIST 模型中的层,这里取3张28*28的图像
|
|
nn.Flatten
将每个 2D 28x28 图像转换为 784 个像素值的连续数组
|
|
nn.Linear
使用其存储的权重和偏差对输入应用线性变换
|
|
nn.ReLU
在线性变换之后应用以引入非线性,帮助神经网络学习各种各样的现象
|
|
nn.Sequential
nn.Sequential是一个有序的模块容器,按照定义的相同顺序通过所有模块
|
|
nn.Softmax
logits中值范围为[-infty, infty],nn.Softmax将其缩放为值 [0, 1],表示模型对每个类的预测概率,dim参数表示值总和必须为 1 的维度
|
|
模型参数
神经网络中的许多层都是参数化的,即具有在训练期间优化的相关权重和阈值。通过parameters()或named_parameters()方法访问
|
|
自动微分TORCH.AUTOGRAD
反向传播:根据损失函数相对于给定参数的梯度进行调整
torch.autograd支持自动计算任何计算图的梯度
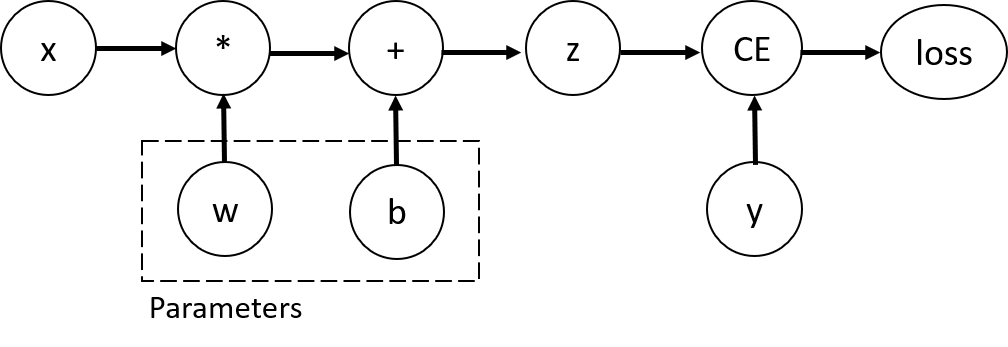
|
|
w和b是我们需要优化的参数,计算损失函数关于这些参数的的梯度,为此设置这些参数张量的requires_grad属性(定义张量时设置该属性为true或后面使用requires_grad_(True)方法设置)
张量的grad_fn属性为反向传播函数的引用
计算梯度
调用backward方法,当进行第二次以上重复调用时添加retain_graph=True参数给backward方法,而且多次重复调用会将结果累加,所以第二次以上调用时需要先将参数张量的grad属性归零
然后就可以检查设置了requires_grad为true的参数张量的grad属性,里面存储了计算的梯度
|
|
禁用梯度跟踪
对requires_grad=True的参数张量只进行正向计算不进行反向传播
- 使用
with torch.no_grad():块包围计算代码
|
|
- 使用张量的detach方法的返回值
|
|
它的requires_grad为false
有关计算图的更多信息
正向传递:
- 运行请求的操作来计算结果张量
- 在 DAG 中维护操作的梯度函数
DAG根上执行backward方法执行反向传播:
- 根据grad_fn属性计算梯度
- 将结果存储在参数张量的grad属性中
- 使用链式法则,一直传播到叶张量
优化模型参数
训练模型是一个迭代过程;在每次迭代中,模型对输出进行猜测,计算其猜测中的误差(损失),收集关于其参数的误差的导数(如我们在上一节中看到的),并使用梯度下降优化这些参数.
超参数
超参数是可调整的参数,可让您控制模型优化过程。不同的超参数值会影响模型训练和收敛速度
- Number of Epochs:迭代数据集的次数
- Batch Size:参数更新前通过网络传播的数据样本数量
- Learning Rate:每个Batch/Epoch更新模型参数的步长。较小学习速度较慢的,较大可能会导致训练期间出现不可预测的行为
|
|
优化循环
优化循环的每次迭代称为一个epoch
每个epoch由两个主要部分组成:
- The Train Loop:迭代训练数据集并尝试收敛到最佳参数
- The Validation/Test Loop:遍历测试数据集以检查模型性能是否正在提高
损失函数
损失函数衡量的是得到的结果与目标值的相异程度,训练目标是最小化的损失函数
使用给定数据样本的输入进行预测,损失函数将结果与真实数据标签值进行比较
常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和 用于分类的nn.NLLLoss(负对数似然)。nn.CrossEntropyLoss结合了nn.LogSoftmax和nn.NLLLoss
将模型的输出 logits 传递给nn.CrossEntropyLoss,这将标准化 logits 并计算预测误差
|
|
优化器
优化算法(如SGD随机梯度下降,ADAM 和 RMSProp)定义了这个过程是如何执行的。所有优化逻辑都封装在optimizer对象中。
|
|
训练循环中,优化分三步进行
- 调用optimizer.zero_grad()方法重置模型参数的梯度
- 调用loss.backward()方法反向传播预测损失
- 调用optimizer.step()方法通过反向传播的梯度调整参数张量
保存和加载模型
保存和加载模型权重
torch.save函数保存张量的信息,可以只保存参数(model的state_dict方法),也可以保存包括形状的所有信息(依赖于pickle模块)
|
|
使用model.load_state_dict()方法加载模型参数,使用torch.load函数加载整个模型
|
|