golang-学习笔记-Goroutines和Channels
在写过很多go代码之后,感觉自己并没有完全掌握go语言,还有很多知识盲区,所以有了这个go学习笔记系列,本系列是作者跟着电子书重新复习go语言相关内容的笔记
Goroutines
|
|
Channels
使用内置的make函数,我们可以创建一个channel:
|
|
发送和接受值:
|
|
使用内置的close函数就可以关闭一个channel:
|
|
不带缓存的Channels
无缓冲会阻塞单方的读取和写入
基于无缓存Channels的发送和接收操作将导致两个goroutine做一次同步操作。无缓存Channels有时候也被称为同步Channels。
当通过一个无缓存Channels发送数据时,接收者收到数据发生在唤醒发送者goroutine之前(译注:happens before,这是Go语言并发内存模型的一个关键术语!)
串联的Channels(Pipeline)
channel被关闭后,写入数据将导致panic异常。读出数据不再阻塞,会立即返回一个零值。
测试一个channel是否被关闭,多接收一个布尔值ok,ture表示成功从channels接收到值,false表示channels已经被关闭并且里面没有值可接收。
|
|
Go语言的range循环可直接在channels上面迭代。它依次从channel接收数据,当channel被关闭并且没有值可接收时跳出循环。
并不需要关闭每一个channel。不管一个channel是否被关闭,当它没有被引用时将会被Go语言的垃圾自动回收器回收。
go 匿名函数可以直接使用上下文中的channel不需要传给它
单方向的Channel
- 类型chan<- int表示一个只发送int的channel,只能发送不能接收
- 类型<-chan int表示一个只接收int的channel,只能接收不能发送
无法使用make创建单向channel(这也不符合常理),可以定义单向channel变量然后将创建的channel赋值给它,通常用于函数传参
带缓存的Channels
带缓存的Channel内部持有一个元素队列。队列大小为make的第2个参数。
读空队列阻塞,写满队列阻塞。
channel内部缓存的容量,可以用内置的cap函数获取:
|
|
内置的len函数返回channel内部缓存队列中有效元素的个数:
|
|
channel读写特性
- nil channel读写都会永远阻塞
- 发送关闭的channel会panic
- 读取关闭的channel获取一个nil
- 关闭已经关闭的channel会panic
channel为什么是并发安全的
问的chatgpt
- 原子性操作:在Go语言中,对Channel的操作是原子性的
- 内置同步机制:Channel内部实现了同步机制,它使用了锁和其他同步原语来保证并发操作的安全性
- 顺序访问保证:Channel在发送和接收数据时是按顺序进行的
不要用channel关闭信号传递信息
不要通过chan的关闭信号来传递消息,一个chan只传递一种信息,要实现关闭管道可以通过额外设置一个chan来专门监听关闭chan
并发的循环
|
|
基于select的多路复用
对于chan的select不是基于事件触发而是基于轮询
select是Golang在语言层面提供的多路IO复用的机制,其可以检测多个channel是否ready(即是否可读或可写)
|
|
select会等待case中有能够执行的case时去执行,当条件满足时,select才会去通信并执行case之后的语句;这时候其它通信是不会执行的
一个没有任何case的select语句写作select{},会永远地等待下去
多个case同时就绪时,select会随机地选择一个执行,这样来保证每一个channel都有平等的被select的机会
default来设置当其它的操作都不能够马上被处理时程序需要执行哪些逻辑,具有default的select不会阻塞
for循环中的select反复地非阻塞读取channel的操作叫做“轮询channel”
channel的零值是nil,对一个nil的channel发送和接收操作会永远阻塞
并发的退出
读取被关闭channel可以立即被执行,并且会产生零值。不要向channel发送值,而是用关·闭一个channel来进行广播。向关闭的channel发送消息会panic
不要通过chan的关闭信号来传递消息,一个chan只传递一种信息,要实现关闭管道可以通过额外设置一个chan来专门监听关闭chan的信息,在需要关闭的时候传送该信息
不要关闭接收端的通道,如果通道有多个并发发送方,则不要关闭通道
channel底层
type hchan struct
属性
- qcount uint:剩余元素个数
- dataqsiz uint:环形队列长度,最大存放元素个数
- buf unsafe.Pointer:指针指向环形队列
- elemsize uint16:元素大小
- closed uint32:关闭状态
- sendx uint:当前写入的索引
- recvx uint:当前读取的索引
- sendq waitq:等待写消息的goroutine队列
- recvq waitq:等待读消息的goroutine队列
- lock mutex:互斥锁


读写流程
向nil管道读或写数据都会导致goroutine死锁
关闭channel时会把recvq中的G全部唤醒,并给他们nil数据。把sendq中的G全部唤醒,并让这些G触发panic。
其他panic场景:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
基于共享变量的并发
sync.Mutex互斥锁
|
|
可以和defer一起用:
|
|
sync.RWMutex读写锁
|
|
它组合了Mutex,Lock()和Unlock()方法会调用Mutex可以看作写锁
sync.Once惰性初始化
|
|
竞争条件检测
见原文
Go的runtime和工具链为我们装备了一个复杂但好用的动态分析工具,竞争检查器(the race detector)。
Goroutines,线程和进程
go修养之路 对于操作系统而言进程、线程以及Goroutine协程的区别
动态栈
每一个OS线程都有一个固定大小的内存块(一般会是2MB)来做栈,这个栈会用来存储当前正在被调用或挂起(指在调用其它函数时)的函数的内部变量。
一个goroutine会以一个很小的栈开始其生命周期,一般只需要2KB。栈的大小会根据需要动态地伸缩。
Goroutine调度
OS线程会被操作系统内核调度。每几毫秒触发硬件中断,调用scheduler内核函数。这个函数会挂起当前执行的线程并将它的寄存器内容保存到内存中,检查线程列表并决定下一次哪个线程可以被运行,并从内存中恢复该线程的寄存器信息,然后恢复执行该线程的现场并开始执行线程。
操作系统线程是被内核所调度,从一个线程向另一个“移动”需要完整的上下文切换,也就是说,保存一个用户线程的状态到内存,恢复另一个线程的到寄存器,然后更新调度器的数据结构。这几步操作很慢,因为其局部性很差需要几次内存访问,并且会增加运行的cpu周期。
Go的运行时包含了其自己的调度器,这个调度器使用了一些技术手段,比如m:n调度,因为其会在n个操作系统线程上多工(调度)m个goroutine。Go调度器的工作和内核的调度是相似的,但是这个调度器只关注单独的Go程序中的goroutine(译注:按程序独立)。
和操作系统的线程调度不同的是,Go调度器并不是用一个硬件定时器,而是被Go语言“架构”本身进行调度的。这种调度方式不需要进入内核的上下文,所以重新调度一个goroutine比调度一个线程代价要低得多。
GOMAXPROCS
Go的调度器使用了一个叫做GOMAXPROCS的变量来决定会有多少个操作系统的线程同时执行Go的代码。其默认的值是运行机器上的CPU的核心数,所以在一个有8个核心的机器上时,调度器一次会在8个OS线程上去调度GO代码。
可以用GOMAXPROCS的环境变量来显式地控制这个参数,或者也可以在运行时用runtime.GOMAXPROCS函数来修改它并返回原来的值(-1不会修改仅返回原来的值)。
Goroutine没有ID号
goroutine没有可以被程序员获取到的身份(id)的概念。
占用内存
进程占用多少内存:4g(32位)
线程占用多少内存:4~64Mb
协程占用多少内存:2.5KB
切换成本
协程:几十ns
限定goroutine数量的简单方法
不限制goroutine数量会导致内存占用超出限制主进程崩溃
- 有buffer的channel来限制
新建goroutine处理请求前发送消息给channel,处理完后消费channel,最后n个goroutine未结束main协程就结束了,导致未执行
|
|
- channel与sync同步组合方式
使用sync.WaitGroup{}让main等待所有goroutine执行完毕
|
|
- 利用无缓冲channel与任务发送/执行分离方式
复用goroutine,将任务和处理分离,channel不再是限制数量的信号,而是任务,goroutine是固定的
|
|
Golang 中常用的3种并发模型
- 通过channel通知实现并发控制:实现简单,清晰易懂
- 通过sync包中的WaitGroup实现并发控制:子协程个数动态可调整
- Context上下文,实现并发控制:对子协程派生出来的孙子协程的控制
go中如何监听一组channels
- reflect.Select
- “aggregate” channel
- select
GMP模型
p的结构体片段:
|
|
有关P和M的个数问题
P的数量由启动时环境变量$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定
M的数量默认10000但是内核一般很难支持这么多线程数,另外runtime/debug中的SetMaxThreads函数可以设置M的最大数量
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
P和M何时会被创建
P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P
M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M
设计策略
- 复用线程:避免频繁的创建、销毁线程,而是对线程的复用
- work stealing机制:本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程
- hand off机制:本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行
- 利用并行:最多有GOMAXPROCS个线程分布在多个CPU上同时运行
- 抢占:一个goroutine最多占用CPU 10ms
- 全局G队列:当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G
go func()流程
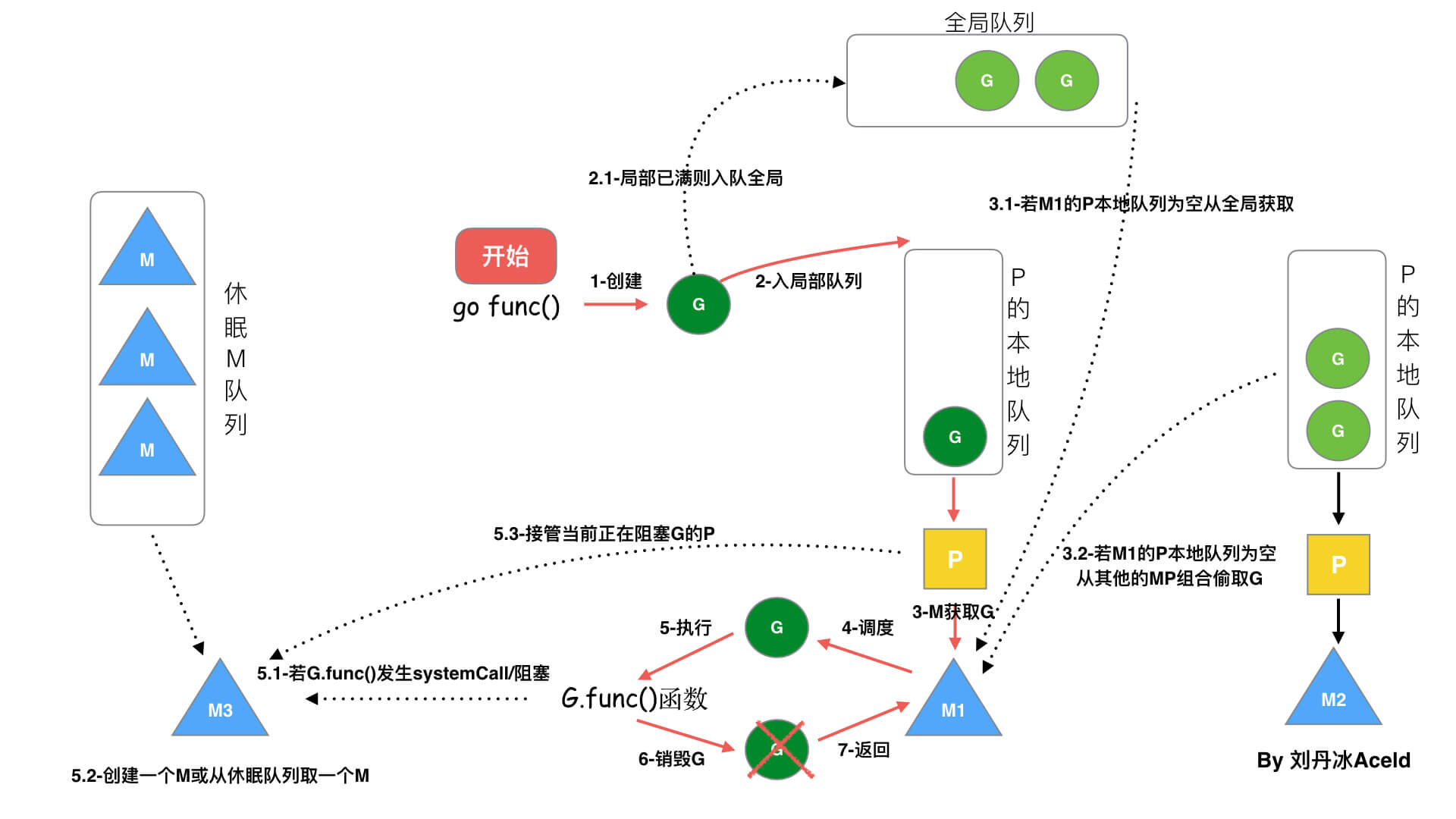
当本地队列满的时候新的G在放入全局队列的同时会把本地队列的一般G也放到全局队列里面
调度器G0生命周期
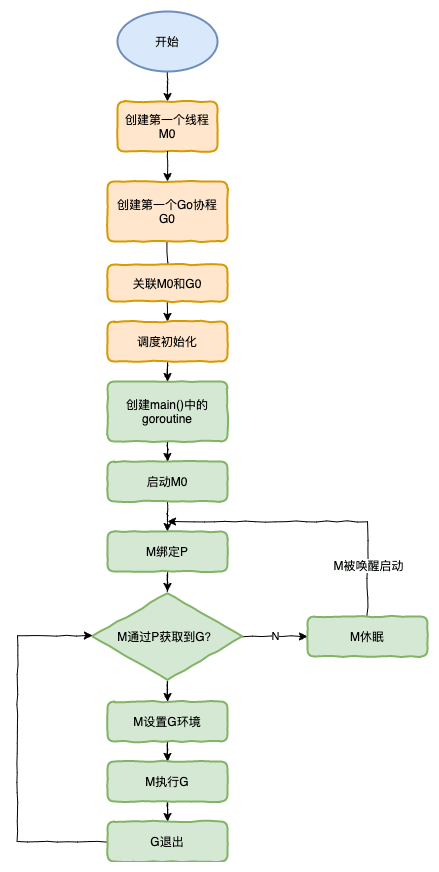
调度下一个协程
- 每调度61次,从GRQ尝试获取队头的G,执行
- 检查runnext,如果存在且上一个协程运行不超过10ms,则执行runnext对应的协程
- 尝试从P的队列中按照G的加入顺序获取,获取成功则切换
- 从GRQ中获取,从队头开始获取G作为下一个执行的队列,同时从GRQ中获取协程继续执行,最多获取128。
n := sched.runqsize/gomaxprocs + 1 - 检查网络阻塞的netpoller,获取摆脱网络阻塞状态的协程列表(相当于调用epoll_wait 获取就绪状态的套接字),获取第一个协程继续执行,将其余摆脱网络阻塞状态的协程放回GRQ的队尾
- 从其余的P上获取协程执行(stealing)